TOLERANT Match Pseudonymization

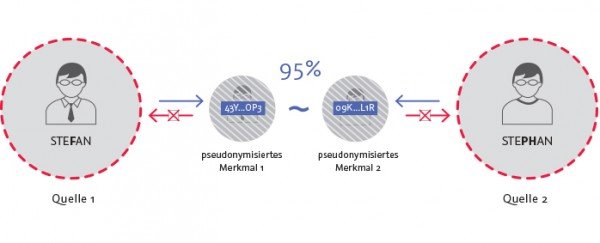
If personal characteristics – e.g. name, address, telephone number – are replaced by pseudonyms, similar data records are no longer recognized with today’s standard methods, even in the case of minor deviations. TOLERANT Software provides a solution for fuzzy searches on fully pseudonymized data. You will then find e.g. Stefan ~ Stephan, although the data contains 43Y…OP3 or 09K…L1R.
Extension for TOLERANT Match
TOLERANT Match is our standard product for fast as an arrow, accurate customer search and duplicate detection in large data sets. We have integrated a method described in the literature under the keyword “Privacy preserving record linkage”, which is now available alongside other matching methods. In the future, users of TOLERANT Match will be able to easily combine the pseudonymized search with the non-pseudonymized search in one matching process.
Tool for preprocessing
For the pseudonymization of the data, an independent tool for pre-processing the data has been developed. With this tool, party A (data provider) can perform pseudonymization and pass the pseudonymized data to party B for further processing. Data processing of pseudonymized data by a service provider is also conceivable, where the data processing itself takes place on “neutral” territory. For individual requests, a pseudonymization proxy can perform this task.
Batch or Service Mode
TOLERANT Match offers two basic modes of use, which are also available for the pseudonymized features. In batch mode, large data sets can be compared quickly. Single queries are possible in service mode, which can then be used e.g. for interactive data collection. With “TOLERANT Match / Pseudonymization” the following application scenarios can be realized.
Application scenarios
Blocking lists for deleted customers
Companies have to comply with deletion requests from customers. However, a literal implementation means that the company cannot store the information that the customer no longer wants to be contacted. So the customer may receive unsolicited mail in the future. A countermeasure would be to add the customer data in anonymized form to a blacklist and to use this for checking before future letters are sent. However, with today’s standard procedures, this check is not error-tolerant. Even minor deviations in the spelling of the name or address mean that the customer is not found on the blacklist.
Checking against sanctions or PEP lists
Legal regulations require the regular checking of creditors and debtors against so-called terror and sanctions lists, as well as the identification of politically exposed persons (PEP). For small and medium-sized enterprises (SMEs), this obligation poses a problem because it is not worthwhile to procure the corresponding software. Instead, such companies can use PEP and sanctions list checks as a service. For data protection reasons, however, many companies are reluctant to give their customer data out. The alternative of releasing only anonymized data is not very practical because it usually does not involve error-tolerant checks. But this is precisely what is important for sanctions lists, because they often contain typing and transmission errors.
Calculation of analytical models
For meaningful analytical models, the broadest possible database should be used. If you want to calculate such models directly, however, your customers’ consent for data transmission and use is required.
With pseudonymization, you can have models calculated by neutral third parties – e.g., service providers – even without customer consent. The relevant target group then determined can be de-pseudonymized and addressed again if the relevant consent is available.
Market research
Let us assume that data on the same person is available in different databases, e.g. in the results of medical studies. Linking these data sets on a person-by-person basis would enable further insights, but the hurdles for this are very high, especially in Germany. A procedure accepted under data protection law for such cases uses a trustee who determines the related personal data of the different inventories, but passes them on to the data user only in anonymized or pseudonymized form. In this case, the data providers must extend their trust to the data trustee. Even further protection of personal data is achieved if it is handed over to the data trustee only in anonymized form. The extension of the area of trust is not necessary in this case. However, the data fiduciary would then not be able to perform error-tolerant matching with the procedures commonly used today. Even minor typing errors would prevent the desired findings from being obtained when comparing the various data sets.
Data enrichment by external service providers
Service providers who offer valuable information – e.g., company data, risk assessments, communications data – for enrichment face a dilemma. Either companies trust them with their customer data or they must deliver their valuable data to companies for internal enrichment. With fault-tolerant search and pseudonymization, both approaches are possible without risk.
Anwendungsszenarien
Sperrlisten für gelöschte Kunden
Unternehmen müssen Löschaufforderungen von Kunden nachkommen. Allerdings bedeutet eine buchstäbliche Umsetzung, dass das Unternehmen die Information, dass der Kunde nicht mehr angeschrieben werden will, nicht speichern kann. Es kann also vorkommen, dass der Kunde künftig unerwünschte Post erhält. Ein Gegenmittel wäre, die Kundendaten in anonymisierter Form einer Sperrliste hinzuzufügen und diese vor künftigen Anschreiben zur Prüfung heranzuziehen. Mit heute üblichen Verfahren erfolgt diese Prüfung allerdings nicht fehlertolerant. Schon kleine Abweichungen der Schreibweise von Name oder Adresse führen dazu, dass der Kunde auf der Sperrliste nicht gefunden wird.
Prüfung gegen Sanktions- oder PEP-Listen
Gesetzliche Regelungen fordern die regelmäßige Überprüfung von Kreditoren und Debitoren gegen sogenannte Terror- und Sanktionslisten, sowie die Identifikation von politisch exponierten Personen (PEP). Für kleine und mittlere Unternehmen (KMU) stellt diese Verpflichtung ein Problem dar, weil sich die Beschaffung entsprechender Software nicht lohnt. Stattdessen können solche Unternehmen PEP- und Sanktionslistenprüfungen als Dienstleistung nutzen. Aus Datenschutzgründen jedoch scheuen sich viele Unternehmen, ihre Kundendaten außer Haus zu geben. Die Alternative, nur anonymisierte Daten herauszugeben, ist wenig praktikabel, weil dabei meist keine fehlertolerante Überprüfung erfolgt. Genau das aber ist für Sanktionslisten wichtig, weil sie oft Schreib- und Übermittlungsfehler enthalten.
Berechnung analytischer Modelle
Für aussagekräftige analytische Modelle sollte eine möglichst breite Datenbasis genutzt werden. Falls Sie solche Modelle direkt berechnen wollen, ist allerdings eine Zustimmung Ihrer Kunden für eine Datenübertragung und -nutzung erforderlich.
Mit einer Pseudonymisierung können Sie Modelle auch ohne Kundenzustimmung durch neutrale Dritte – z.B. Dienstleister – berechnen lassen. Die dann ermittelte relevante Zielgruppe kann bei Vorliegen der entsprechenden Zustimmung wieder de-pseudonymisiert und angesprochen werden.
Marktforschung
Nehmen wir an, dass Daten zur selben Person in unterschiedlichen Datenbeständen vorliegen, z.B. in Ergebnissen medizinischer Studien. Die personenbezogene Verknüpfung dieser Datenbestände würde weitergehende Erkenntnisse ermöglichen, jedoch sind die Hürden dafür besonders in Deutschland sehr hoch. Ein datenschutzrechtlich akzeptiertes Verfahren für solche Fälle nutzt einem Treuhänder, der die zusammengehörenden Personendaten der verschiedenen Bestände ermittelt, an den Datennutzer jedoch nur in anonymisierter oder pseudonymisierter Form weitergibt. In diesem Fall müssen die Datengeber ihren Vertrauensbereich auf den Datentreuhänder ausdehnen. Ein noch weitergehender Schutz der Personendaten wird erreicht, wenn sie dem Datentreuhänder nur anonymisiert ausgehändigt werden. Die Ausdehnung des Vertrauensbereichs ist dabei nicht notwendig. Allerdings kann der Datentreuhänder dann mit heute üblichen Verfahren keinen fehlertoleranten Abgleich durchführen. Schon geringfügige Schreibfehler würden die gewünschten Erkenntnisse beim Abgleich der verschiedenen Datenbestände verhindern.
Datenanreicherung durch externe Dienstleister
Dienstleister, die wertvolle Informationen – z.B. Firmendaten, Risikobewertungen, Kommunikationsdaten – zur Anreicherung anbieten, sind in einem Dilemma. Entweder vertrauen Unternehmen ihnen ihre Kundendaten an oder sie müssen ihre wertvollen Daten an die Unternehmen zur internen Anreicherung liefern. Mit einer fehlertoleranten Suche und Pseudonymisierung sind beide Ansätze ohne Risiko möglich.
 Shutterstock
Shutterstock Shutterstock
Shutterstock